
hbase 微博系统设计
时间:2024-09-18 来源:网络 人气:
基于HBase的微博系统设计
摘要
随着互联网技术的飞速发展,微博作为一种新兴的社交媒体平台,已经成为人们日常生活中不可或缺的一部分。本文将探讨如何利用HBase这一分布式数据库技术,设计并实现一个高效、可扩展的微博系统。
一、引言
微博系统作为社交媒体的一种,具有用户基数大、数据量庞大、实时性强等特点。传统的数据库系统在处理这类大数据量、高并发访问的场景时,往往难以满足性能需求。HBase作为Hadoop生态系统中的一个重要组件,具有分布式、可扩展、高性能等特点,非常适合用于构建微博系统。
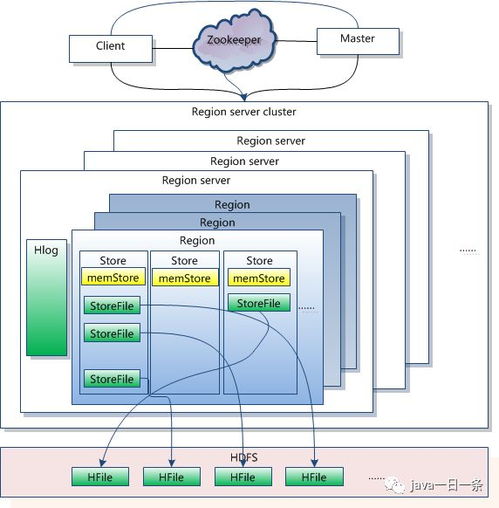
二、HBase简介

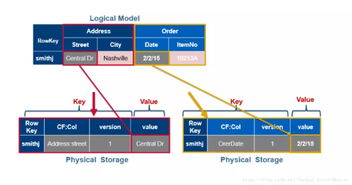
HBase是基于Google的BigTable模型设计的一个分布式、可扩展的oSQL数据库。它存储在HDFS上,支持大规模数据存储和实时访问。HBase的数据模型由行键、列族和列限定符组成,每个单元格可以存储多个版本的数据。
三、微博系统设计
1. 系统架构
基于HBase的微博系统采用分布式架构,主要包括以下几个模块:
用户模块:负责用户注册、登录、个人信息管理等。
微博模块:负责发布、转发、评论微博,以及查看微博列表等。
消息模块:负责私信、关注、粉丝管理等。
数据存储模块:基于HBase存储用户数据、微博数据、消息数据等。
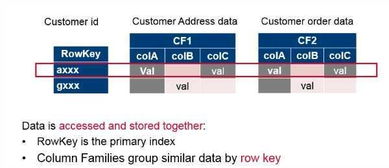
2. 数据模型设计
微博系统的数据模型主要包括以下几种:
用户表:存储用户信息,包括用户ID、昵称、头像、简介等。
微博表:存储微博内容,包括微博ID、用户ID、内容、发布时间、点赞数、评论数等。
评论表:存储评论内容,包括评论ID、微博ID、用户ID、评论内容、评论时间等。
私信表:存储私信内容,包括私信ID、发送者ID、接收者ID、内容、发送时间等。
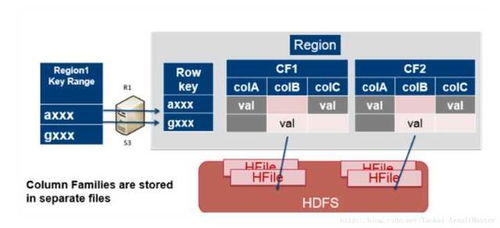
3. 索引设计
为了提高查询效率,需要对微博系统中的热点数据建立索引。以下是一些常见的索引设计:
用户ID索引:根据用户ID快速查询用户信息。
微博ID索引:根据微博ID快速查询微博内容。
时间戳索引:根据发布时间查询微博内容。
4. 性能优化
为了提高微博系统的性能,可以从以下几个方面进行优化:
合理设计RowKey:RowKey的设计应尽量保证数据的均匀分布,避免热点问题。
分区策略:根据数据特点,合理划分Regio,提高数据访问效率。
缓存机制:对热点数据使用缓存,减少对HBase的访问次数。
读写分离:通过HBase的客户端实现读写分离,提高系统吞吐量。
四、总结
基于HBase的微博系统设计,充分利用了HBase的分布式、可扩展、高性能等特点,能够满足大规模微博系统的需求。在实际应用中,可以根据具体场景对系统进行优化,提高系统的性能和稳定性。
标签
相关推荐



教程资讯
教程资讯排行









