
amazon推荐系统,技术架构与算法解析
时间:2024-11-13 来源:网络 人气:
揭秘Amazon推荐系统:技术架构与算法解析

在当今电子商务领域,Amazon作为全球最大的在线零售商之一,其推荐系统在提升用户购物体验和增加销售额方面发挥着至关重要的作用。本文将深入解析Amazon推荐系统的技术架构和核心算法,带您一窥其背后的秘密。
一、Amazon推荐系统的技术架构
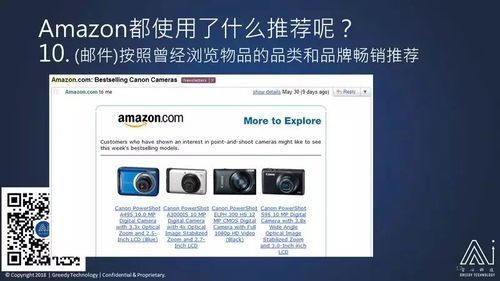
Amazon推荐系统采用了一种分布式、可扩展的技术架构,主要包括以下几个关键组件:
数据采集与处理:通过爬虫技术收集用户行为数据,包括浏览、搜索、购买等,并对数据进行清洗、去重、转换等预处理操作。
特征工程:根据业务需求,提取用户和物品的特征,如用户年龄、性别、购买历史、物品类别、价格等。
模型训练与优化:利用机器学习算法对用户和物品的特征进行建模,并通过在线学习或批量学习的方式不断优化模型。
推荐生成与展示:根据用户特征和物品特征,生成个性化的推荐列表,并在网页或移动端展示给用户。
二、Amazon推荐系统的核心算法

Amazon推荐系统采用了多种算法,以下列举几种常见的核心算法:
1. 协同过滤算法
协同过滤算法是Amazon推荐系统中最常用的算法之一,主要包括以下两种类型:
基于用户的协同过滤:根据具有相似兴趣的用户推荐物品。
基于物品的协同过滤:根据用户过去喜欢的物品推荐相似物品。
2. 基于内容的推荐算法
基于内容的推荐算法根据物品的属性和用户的历史行为推荐相似物品,主要方法包括:
关键词匹配:根据物品的标题、描述等文本信息提取关键词,并与用户的历史行为进行匹配。
文本分类:将物品和用户的历史行为进行文本分类,然后根据分类结果推荐相似物品。
3. 深度学习算法
深度学习算法在Amazon推荐系统中扮演着越来越重要的角色,以下列举几种常用的深度学习算法:
卷积神经网络(CNN):用于提取物品的视觉特征。
循环神经网络(RNN):用于处理用户的历史行为序列。
生成对抗网络(GAN):用于生成新的物品推荐列表。
三、Amazon推荐系统的优势与挑战

Amazon推荐系统具有以下优势:
个性化推荐:根据用户的历史行为和兴趣,提供个性化的推荐结果。
实时推荐:根据用户的行为变化,实时更新推荐结果。
可扩展性:采用分布式架构,可轻松扩展到海量数据。
然而,Amazon推荐系统也面临着以下挑战:
数据稀疏性:用户和物品的交互数据往往稀疏,给推荐算法带来挑战。
冷启动问题:新用户或新物品缺乏历史数据,难以进行有效推荐。
算法偏差:推荐算法可能存在偏差,导致推荐结果不公平。
相关推荐


教程资讯
教程资讯排行









