
kafka 日志系统,高效、可靠的分布式日志解决方案
时间:2024-10-07 来源:网络 人气:
Kafka日志系统:高效、可靠的分布式日志解决方案
随着大数据时代的到来,日志数据量呈爆炸式增长,如何高效、可靠地处理这些日志数据成为企业关注的焦点。Kafka作为一种高性能的分布式消息队列系统,在日志系统中扮演着重要角色。本文将详细介绍Kafka日志系统的架构、特点和应用场景。
一、Kafka日志系统架构
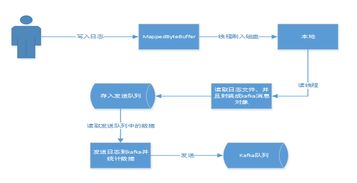
Kafka日志系统主要由以下几个组件构成:
生产者(Producer):负责将日志数据发送到Kafka集群。
消费者(Consumer):从Kafka集群中读取日志数据,并进行后续处理。
Broker:Kafka集群中的节点,负责存储日志数据,并处理生产者和消费者的请求。
主题(Topic):日志数据的分类标识,每个主题可以包含多个分区(Partition)。
分区(Partition):日志数据的存储单元,每个分区存储着同一主题的日志数据。
二、Kafka日志系统特点
1. 高吞吐量:Kafka采用分布式架构,可以水平扩展,从而实现高吞吐量的日志处理。
2. 可靠性:Kafka采用副本机制,确保数据不丢失,即使在发生故障的情况下也能保证数据的可靠性。
3. 可扩展性:Kafka支持水平扩展,可以轻松应对日志数据量的增长。
4. 低延迟:Kafka设计上注重消息传递而非消息处理,从而实现低延迟的日志处理。
5. 易于集成:Kafka支持多种编程语言,可以方便地与其他系统进行集成。
三、Kafka日志系统应用场景
1. 日志收集:Kafka可以收集来自各种来源的日志数据,如服务器、应用程序、网络设备等。
2. 日志分析:Kafka可以将收集到的日志数据发送到其他系统,如Elasticsearch、Hadoop等,进行日志分析。
3. 实时监控:Kafka可以实时监控日志数据,及时发现异常情况。
4. 数据归档:Kafka可以将历史日志数据归档到其他存储系统,如HDFS、OSS等。
5. 流处理:Kafka可以与其他流处理框架(如Apache Flink、Spark Streaming等)结合,实现实时数据处理。
四、Kafka日志系统实践
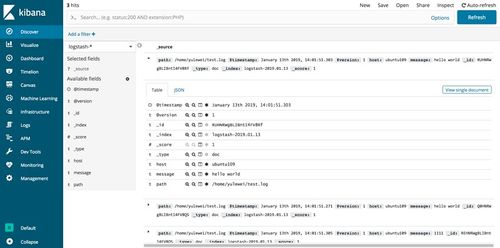
1. 环境搭建:需要搭建Kafka集群,包括生产者、消费者和Broker节点。
2. 主题创建:创建一个主题,用于存储日志数据。
3. 生产者配置:配置生产者,将日志数据发送到Kafka集群。
4. 消费者配置:配置消费者,从Kafka集群中读取日志数据,并进行后续处理。
5. 日志处理:根据实际需求,对日志数据进行处理,如分析、监控、归档等。
Kafka日志系统凭借其高效、可靠、可扩展等特点,成为企业处理海量日志数据的理想选择。通过本文的介绍,相信大家对Kafka日志系统有了更深入的了解。在实际应用中,可以根据具体需求,灵活运用Kafka日志系统,实现高效、可靠的日志处理。
相关推荐

教程资讯
教程资讯排行









